파인튜닝 시작하기
파인튜닝 모의 실습은 아래와 같이 구성되어 있습니다.
1. 새 모델 만들기
기존 AI 모델을 재훈련하기 위한 데이터셋을 만듭니다.
데이터 선택 버튼 → 새 파일 생성 버튼 → 파일명 입력 → 만들기 버튼 순으로 데이터셋을 만들 수 있으며, 이번 수업에서는 경상도 사투리를 사용하는 50대 아주머니의 데이터셋을 사용합니다.
이후 학습 데이터 파일 저장소에서 해당 데이터셋에 대한 적용 버튼을 눌러, 데이터셋 파일을 적용합니다.
2. 하이퍼파라미터 설정
파인튜닝을 위한 하이퍼파라미터를 설정합니다.
배치 크기, 학습률, 에폭 수를 설정할 수 있으며, 이는 OpenAI에서 제공하는 파인튜닝 하이퍼파라미터와 동일합니다.
3. 파인튜닝 시작하기
파인튜닝 실행 버튼을 누르면, 업로드한 학습 데이터와 설정한 하이퍼파라미터를 기반으로 파인튜닝이 시작됩니다.
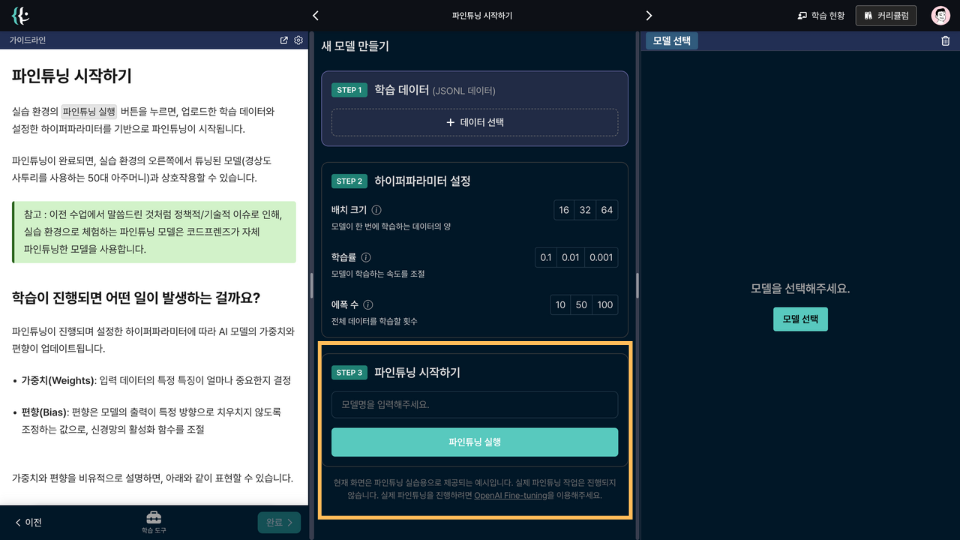
파인튜닝이 완료되면, 실습 환경의 오른쪽에서 튜닝된 모델(경상도 사투리를 사용하는 50대 아주머니)과 상호작용할 수 있습니다.
참고 : 이전 수업에서 말씀드린 것처럼 정책적/기술적 이슈로 인해, 실습 환경으로 체험하는 파인튜닝 모델은 코드프렌즈가 자체 파인튜닝한 모델을 사용합니다.
학습이 진행되면 어떤 일이 발생하는 걸까요?
파인튜닝이 진행되며 설정한 하이퍼파라미터에 따라 AI 모델의 가중치와 편향이 업데이트됩니다.
-
가중치(Weights): 입력 데이터의 특정 특징이 얼마나 중요한지 결정
-
편향(Bias): 편향은 모델의 출력이 특정 방향으로 치우치지 않도록 조정하는 값으로, 신경망의 활성화 함수를 조절
가중치와 편향을 비유적으로 설명하면, 아래와 같이 표현할 수 있습니다.
-
가중치는 빵을 만들 때 각 재료의 양을 조절하는 것과 같습니다.
-
편향은 맛의 기본값으로, 빵에 기본적으로 추가되는 설탕을 얼마나 넣을지를 결정하는 것과 같습니다.
-
학습 과정은 주기적으로 맛을 보면서, 재료의 양을 조금씩 조절하며 최적의 맛을 찾아가는 과정입니다.
파인튜닝이 진행되는 과정
파인튜닝은 다음과 같은 과정을 거쳐 가중치와 편향 값을 업데이트합니다.
1. 초기화 (Initialization)
AI 모델 학습을 처음 시작할 때, 가중치와 편향은 무작위로 설정됩니다.
파인튜닝 시에는 이전 모델의 가중치와 편향을 초기값으로 사용합니다.
2. 순전파 (Forward Propagation)
입력 데이터가 모델을 통해 전달됩니다. 각 입력 값은 가중치와 곱해지고 편향이 더해져서 출력 값이 계산됩니다.
예를 들어, y = wx + b에서 y는 출력, w는 가중치, x는 입력, b는 편향입니다.
3. 손실 계산 (Loss Calculation)
모델의 예측 값(출력)과 실제 값(정답) 사이의 차이를 계산하여 손실 값을 구합니다. 손실 값은 모델의 예측이 얼마나 잘못되었는지를 나타냅니다.
예를 들어, 예측 값이 5이고 실제 값이 3이면, 손실은 이 둘의 차이입니다. (예: 평균 제곱 오차 함수 적용 시, (5-3)^2 = 4)
4. 역전파 (Backpropagation)
손실 값을 줄이기 위해 가중치와 편향을 어떻게 조정할지를 결정합니다.
이를 위해 각 가중치와 편향이 손실 값에 얼마나 기여했는지를 계산합니다. 이 과정은 미분을 사용하여 기울기(Gradient)를 구합니다.
5. 가중치와 편향 업데이트
계산된 기울기를 사용하여 가중치와 편향을 업데이트합니다. 이는 손실 값을 줄이는 방향으로 조정됩니다.
다음 수업에서는 지금까지 배운 내용을 바탕으로 간단한 퀴즈를 풀어보겠습니다.
파인튜닝으로 학습을 진행하면 무엇이 업데이트되는 걸까요?
모델의 입력 데이터
모델의 가중치와 편향
모델의 하드웨어 구성
모델의 학습률
Lecture
AI Tutor
Design
Upload
Notes
Favorites
Help